|
|
||
|---|---|---|
| .github | ||
| cluster | ||
| configs | ||
| configs_template | ||
| dataset_raw | ||
| diffusion | ||
| edgetts | ||
| filelists | ||
| inference | ||
| logs/44k | ||
| modules | ||
| onnxexport | ||
| pretrain | ||
| raw | ||
| trained | ||
| vdecoder | ||
| vencoder | ||
| .gitattributes | ||
| .gitignore | ||
| .ruff.toml | ||
| LICENSE | ||
| README.md | ||
| README_zh_CN.md | ||
| compress_model.py | ||
| data_utils.py | ||
| export_index_for_onnx.py | ||
| flask_api.py | ||
| flask_api_full_song.py | ||
| inference_main.py | ||
| models.py | ||
| onnx_export.py | ||
| onnx_export_old.py | ||
| preprocess_flist_config.py | ||
| preprocess_hubert_f0.py | ||
| requirements.txt | ||
| requirements_onnx_encoder.txt | ||
| requirements_win.txt | ||
| resample.py | ||
| shadowdiffusion.png | ||
| sovits4_for_colab.ipynb | ||
| spkmix.py | ||
| train.py | ||
| train_diff.py | ||
| train_index.py | ||
| utils.py | ||
| wav_upload.py | ||
| webUI.py | ||
{kind=link}
README.md

SoftVC VITS Singing Voice Conversion
![]()
This round of limited time update is coming to an end, the warehouse will enter the Archieve state, please know
✨ A studio that contains visible f0 editor, speaker mix timeline editor and other features (Where the Onnx models are used) : MoeVoiceStudio
✨ A fork with a greatly improved user interface: 34j/so-vits-svc-fork
✨ A client supports real-time conversion: w-okada/voice-changer
This project differs fundamentally from VITS, as it focuses on Singing Voice Conversion (SVC) rather than Text-to-Speech (TTS). In this project, TTS functionality is not supported, and VITS is incapable of performing SVC tasks. It's important to note that the models used in these two projects are not interchangeable or universally applicable.
Announcement
The purpose of this project was to enable developers to have their beloved anime characters perform singing tasks. The developers' intention was to focus solely on fictional characters and avoid any involvement of real individuals, anything related to real individuals deviates from the developer's original intention.
Disclaimer
This project is an open-source, offline endeavor, and all members of SvcDevelopTeam, as well as other developers and maintainers involved (hereinafter referred to as contributors), have no control over the project. The contributors have never provided any form of assistance to any organization or individual, including but not limited to dataset extraction, dataset processing, computing support, training support, inference, and so on. The contributors do not and cannot be aware of the purposes for which users utilize the project. Therefore, any AI models and synthesized audio produced through the training of this project are unrelated to the contributors. Any issues or consequences arising from their use are the sole responsibility of the user.
This project is run completely offline and does not collect any user information or gather user input data. Therefore, contributors to this project are not aware of all user input and models and therefore are not responsible for any user input.
This project serves as a framework only and does not possess speech synthesis functionality by itself. All functionalities require users to train the models independently. Furthermore, this project does not come bundled with any models, and any secondary distributed projects are independent of the contributors of this project.
📏 Terms of Use
Warning: Please ensure that you address any authorization issues related to the dataset on your own. You bear full responsibility for any problems arising from the usage of non-authorized datasets for training, as well as any resulting consequences. The repository and its maintainer, svc develop team, disclaim any association with or liability for the consequences.
- This project is exclusively established for academic purposes, aiming to facilitate communication and learning. It is not intended for deployment in production environments.
- Any sovits-based video posted to a video platform must clearly specify in the introduction the input source vocals and audio used for the voice changer conversion, e.g., if you use someone else's video/audio and convert it by separating the vocals as the input source, you must give a clear link to the original video or music; if you use your own vocals or a voice synthesized by another voice synthesis engine as the input source, you must also state this in your introduction.
- You are solely responsible for any infringement issues caused by the input source and all consequences. When using other commercial vocal synthesis software as an input source, please ensure that you comply with the regulations of that software, noting that the regulations of many vocal synthesis engines explicitly state that they cannot be used to convert input sources!
- Engaging in illegal activities, as well as religious and political activities, is strictly prohibited when using this project. The project developers vehemently oppose the aforementioned activities. If you disagree with this provision, the usage of the project is prohibited.
- If you continue to use the program, you will be deemed to have agreed to the terms and conditions set forth in README and README has discouraged you and is not responsible for any subsequent problems.
- If you intend to employ this project for any other purposes, kindly contact and inform the maintainers of this repository in advance.
📝 Model Introduction
The singing voice conversion model uses SoftVC content encoder to extract speech features from the source audio. These feature vectors are directly fed into VITS without the need for conversion to a text-based intermediate representation. As a result, the pitch and intonations of the original audio are preserved. Meanwhile, the vocoder was replaced with NSF HiFiGAN to solve the problem of sound interruption.
🆕 4.1-Stable Version Update Content
- Feature input is changed to the 12th Layer of Content Vec Transformer output, And compatible with 4.0 branches.
- Update the shallow diffusion, you can use the shallow diffusion model to improve the sound quality.
- Added Whisper-PPG encoder support
- Added static/dynamic sound fusion
- Added loudness embedding
- Added Functionality of feature retrieval from RVC
🆕 Questions about compatibility with the 4.0 model
- To support the 4.0 model and incorporate the speech encoder, you can make modifications to the
config.jsonfile. Add thespeech_encoderfield to the "model" section as shown below:
"model": {
.........
"ssl_dim": 256,
"n_speakers": 200,
"speech_encoder":"vec256l9"
}
🆕 Shallow diffusion
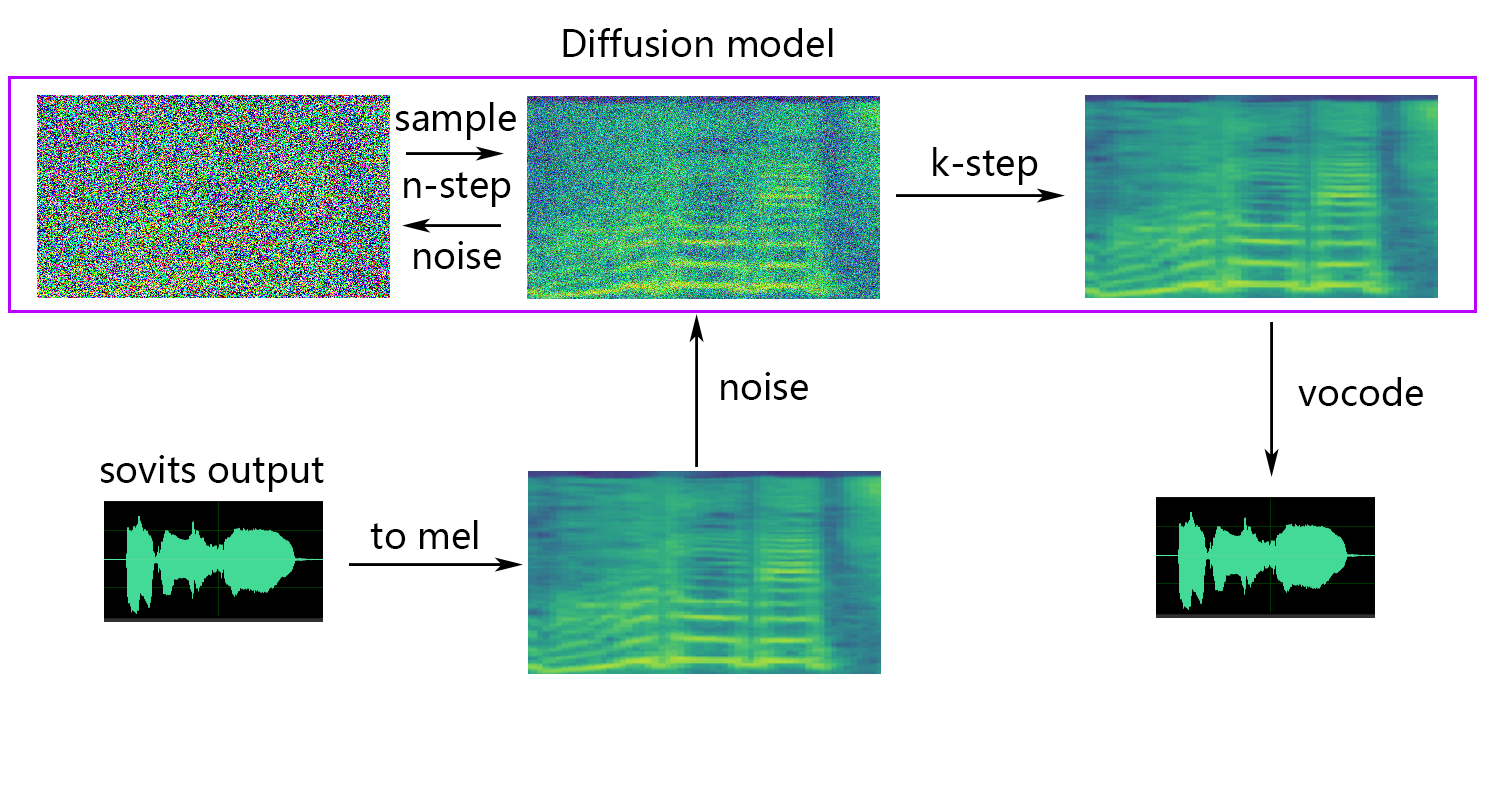
💬 Python Version
Based on our testing, we have determined that the project runs stable on Python 3.8.9.
📥 Pre-trained Model Files
Required
You need to select one encoder from the list below
1. If using contentvec as speech encoder(recommended)
vec768l12 and vec256l9 require the encoder
- ContentVec: checkpoint_best_legacy_500.pt
- Place it under the
pretraindirectory
- Place it under the
Or download the following ContentVec, which is only 199MB in size but has the same effect:
- ContentVec: hubert_base.pt
- Change the file name to
checkpoint_best_legacy_500.ptand place it in thepretraindirectory
- Change the file name to
# contentvec
wget -P pretrain/ https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/hubert_base.pt -O checkpoint_best_legacy_500.pt
# Alternatively, you can manually download and place it in the hubert directory
2. If hubertsoft is used as the speech encoder
- soft vc hubert: hubert-soft-0d54a1f4.pt
- Place it under the
pretraindirectory
- Place it under the
3. If whisper-ppg as the encoder
- download model at medium.pt, the model fits
whisper-ppg - or download model at large-v2.pt, the model fits
whisper-ppg-large- Place it under the
pretraindirectory
- Place it under the
4. If cnhubertlarge as the encoder
- download model at chinese-hubert-large-fairseq-ckpt.pt
- Place it under the
pretraindirectory
- Place it under the
5. If dphubert as the encoder
- download model at DPHuBERT-sp0.75.pth
- Place it under the
pretraindirectory
- Place it under the
6. If WavLM is used as the encoder
- download model at WavLM-Base+.pt, the model fits
wavlmbase+- Place it under the
pretraindirectory
- Place it under the
7. If OnnxHubert/ContentVec as the encoder
- download model at MoeSS-SUBModel
- Place it under the
pretraindirectory
- Place it under the
List of Encoders
- "vec768l12"
- "vec256l9"
- "vec256l9-onnx"
- "vec256l12-onnx"
- "vec768l9-onnx"
- "vec768l12-onnx"
- "hubertsoft-onnx"
- "hubertsoft"
- "whisper-ppg"
- "cnhubertlarge"
- "dphubert"
- "whisper-ppg-large"
- "wavlmbase+"
Optional(Strongly recommend)
-
Pre-trained model files:
G_0.pthD_0.pth- Place them under the
logs/44kdirectory
- Place them under the
-
Diffusion model pretraining base model file:
model_0.pt- Put it in the
logs/44k/diffusiondirectory
- Put it in the
Get Sovits Pre-trained model from svc-develop-team(TBD) or anywhere else.
Diffusion model references Diffusion-SVC diffusion model. The pre-trained diffusion model is universal with the DDSP-SVC's. You can go to Diffusion-SVC's repo to get the pre-trained diffusion model.
While the pretrained model typically does not pose copyright concerns, it is essential to remain vigilant. It is advisable to consult with the author beforehand or carefully review the description to ascertain the permissible usage of the model. This helps ensure compliance with any specified guidelines or restrictions regarding its utilization.
Optional(Select as Required)
NSF-HIFIGAN
If you are using the NSF-HIFIGAN enhancer or shallow diffusion, you will need to download the pre-trained NSF-HIFIGAN model.
- Pre-trained NSF-HIFIGAN Vocoder: nsf_hifigan_20221211.zip
- Unzip and place the four files under the
pretrain/nsf_hifigandirectory
- Unzip and place the four files under the
# nsf_hifigan
wget -P pretrain/ https://github.com/openvpi/vocoders/releases/download/nsf-hifigan-v1/nsf_hifigan_20221211.zip
unzip -od pretrain/nsf_hifigan pretrain/nsf_hifigan_20221211.zip
# Alternatively, you can manually download and place it in the pretrain/nsf_hifigan directory
# URL: https://github.com/openvpi/vocoders/releases/tag/nsf-hifigan-v1
RMVPE
If you are using the rmvpe F0 Predictor, you will need to download the pre-trained RMVPE model.
- download model at rmvpe.zip, this weight is recommended.
- unzip
rmvpe.zip,and rename themodel.ptfile tormvpe.ptand place it under thepretraindirectory.
- unzip
download model at rmvpe.ptPlace it under thepretraindirectory
FCPE(Preview version)
FCPE(Fast Context-base Pitch Estimator) is a dedicated F0 predictor designed for real-time voice conversion and will become the preferred F0 predictor for sovits real-time voice conversion in the future.(The paper is being written)
If you are using the fcpe F0 Predictor, you will need to download the pre-trained FCPE model.
- download model at fcpe.pt
- Place it under the
pretraindirectory
- Place it under the
📊 Dataset Preparation
Simply place the dataset in the dataset_raw directory with the following file structure:
dataset_raw
├───speaker0
│ ├───xxx1-xxx1.wav
│ ├───...
│ └───Lxx-0xx8.wav
└───speaker1
├───xx2-0xxx2.wav
├───...
└───xxx7-xxx007.wav
There are no specific restrictions on the format of the name for each audio file (naming conventions such as 000001.wav to 999999.wav are also valid), but the file type must be `WAV``.
You can customize the speaker's name as showed below:
dataset_raw
└───suijiSUI
├───1.wav
├───...
└───25788785-20221210-200143-856_01_(Vocals)_0_0.wav
🛠️ Preprocessing
0. Slice audio
To avoid video memory overflow during training or pre-processing, it is recommended to limit the length of audio clips. Cutting the audio to a length of "5s - 15s" is more recommended. Slightly longer times are acceptable, however, excessively long clips may cause problems such as torch.cuda.OutOfMemoryError.
To facilitate the slicing process, you can use audio-slicer-GUI or audio-slicer-CLI
In general, only the Minimum Interval needs to be adjusted. For spoken audio, the default value usually suffices, while for singing audio, it can be adjusted to around 100 or even 50, depending on the specific requirements.
After slicing, it is recommended to remove any audio clips that are excessively long or too short.
If you are using whisper-ppg encoder for training, the audio clips must shorter than 30s.
1. Resample to 44100Hz and mono
python resample.py
Cautions
Although this project has resample.py scripts for resampling, mono and loudness matching, the default loudness matching is to match to 0db. This can cause damage to the sound quality. While python's loudness matching package pyloudnorm does not limit the level, this can lead to sonic boom. Therefore, it is recommended to consider using professional sound processing software, such as adobe audition for loudness matching. If you are already using other software for loudness matching, add the parameter -skip_loudnorm to the run command:
python resample.py --skip_loudnorm
2. Automatically split the dataset into training and validation sets, and generate configuration files.
python preprocess_flist_config.py --speech_encoder vec768l12
speech_encoder has the following options
vec768l12
vec256l9
hubertsoft
whisper-ppg
cnhubertlarge
dphubert
whisper-ppg-large
wavlmbase+
If the speech_encoder argument is omitted, the default value is vec768l12
Use loudness embedding
Add --vol_aug if you want to enable loudness embedding:
python preprocess_flist_config.py --speech_encoder vec768l12 --vol_aug
After enabling loudness embedding, the trained model will match the loudness of the input source; otherwise, it will match the loudness of the training set.
You can modify some parameters in the generated config.json and diffusion.yaml
-
keep_ckpts: Keep the the the number of previous models during training. Set to0to keep them all. Default is3. -
all_in_mem: Load all dataset to RAM. It can be enabled when the disk IO of some platforms is too low and the system memory is much larger than your dataset. -
batch_size: The amount of data loaded to the GPU for a single training session can be adjusted to a size lower than the GPU memory capacity. -
vocoder_name: Select a vocoder. The default isnsf-hifigan.
diffusion.yaml
-
cache_all_data: Load all dataset to RAM. It can be enabled when the disk IO of some platforms is too low and the system memory is much larger than your dataset. -
duration: The duration of the audio slicing during training, can be adjusted according to the size of the video memory, Note: this value must be less than the minimum time of the audio in the training set! -
batch_size: The amount of data loaded to the GPU for a single training session can be adjusted to a size lower than the video memory capacity. -
timesteps: The total number of steps in the diffusion model, which defaults to 1000. -
k_step_max: Training can only traink_step_maxstep diffusion to save training time, note that the value must be less thantimesteps, 0 is to train the entire diffusion model, Note: if you do not train the entire diffusion model will not be able to use only_diffusion!
List of Vocoders
nsf-hifigan
nsf-snake-hifigan
3. Generate hubert and f0
python preprocess_hubert_f0.py --f0_predictor dio
f0_predictor has the following options
crepe
dio
pm
harvest
rmvpe
fcpe
If the training set is too noisy,it is recommended to use crepe to handle f0
If the f0_predictor parameter is omitted, the default value is rmvpe
If you want shallow diffusion (optional), you need to add the --use_diff parameter, for example:
python preprocess_hubert_f0.py --f0_predictor dio --use_diff
Speed Up preprocess
If your dataset is pretty large,you can increase the param --num_processes like that:
python preprocess_hubert_f0.py --f0_predictor dio --num_processes 8
All the worker will be assigned to different GPU if you have more than one GPUs.
After completing the above steps, the dataset directory will contain the preprocessed data, and the dataset_raw folder can be deleted.
🏋️ Training
Sovits Model
python train.py -c configs/config.json -m 44k
Diffusion Model (optional)
If the shallow diffusion function is needed, the diffusion model needs to be trained. The diffusion model training method is as follows:
python train_diff.py -c configs/diffusion.yaml
During training, the model files will be saved to logs/44k, and the diffusion model will be saved to logs/44k/diffusion
🤖 Inference
# Example
python inference_main.py -m "logs/44k/G_30400.pth" -c "configs/config.json" -n "君の知らない物語-src.wav" -t 0 -s "nen"
Required parameters:
-m|--model_path: path to the model.-c|--config_path: path to the configuration file.-n|--clean_names: a list of wav file names located in therawfolder.-t|--trans: pitch shift, supports positive and negative (semitone) values.-s|--spk_list: Select the speaker ID to use for conversion.-cl|--clip: Forced audio clipping, set to 0 to disable(default), setting it to a non-zero value (duration in seconds) to enable.
Optional parameters: see the next section
-lg|--linear_gradient: The cross fade length of two audio slices in seconds. If there is a discontinuous voice after forced slicing, you can adjust this value. Otherwise, it is recommended to use the default value of 0.-f0p|--f0_predictor: Select a F0 predictor, options arecrepe,pm,dio,harvest,rmvpe,fcpe, default value ispm(note: f0 mean pooling will be enable when usingcrepe)-a|--auto_predict_f0: automatic pitch prediction, do not enable this when converting singing voices as it can cause serious pitch issues.-cm|--cluster_model_path: Cluster model or feature retrieval index path, if left blank, it will be automatically set as the default path of these models. If there is no training cluster or feature retrieval, fill in at will.-cr|--cluster_infer_ratio: The proportion of clustering scheme or feature retrieval ranges from 0 to 1. If there is no training clustering model or feature retrieval, the default is 0.-eh|--enhance: Whether to use NSF_HIFIGAN enhancer, this option has certain effect on sound quality enhancement for some models with few training sets, but has negative effect on well-trained models, so it is disabled by default.-shd|--shallow_diffusion: Whether to use shallow diffusion, which can solve some electrical sound problems after use. This option is disabled by default. When this option is enabled, NSF_HIFIGAN enhancer will be disabled-usm|--use_spk_mix: whether to use dynamic voice fusion-lea|--loudness_envelope_adjustment:The adjustment of the input source's loudness envelope in relation to the fusion ratio of the output loudness envelope. The closer to 1, the more the output loudness envelope is used-fr|--feature_retrieval:Whether to use feature retrieval If clustering model is used, it will be disabled, andcmandcrparameters will become the index path and mixing ratio of feature retrieval
Shallow diffusion settings:
-dm|--diffusion_model_path: Diffusion model path-dc|--diffusion_config_path: Diffusion config file path-ks|--k_step: The larger the number of k_steps, the closer it is to the result of the diffusion model. The default is 100-od|--only_diffusion: Whether to use Only diffusion mode, which does not load the sovits model to only use diffusion model inference-se|--second_encoding:which involves applying an additional encoding to the original audio before shallow diffusion. This option can yield varying results - sometimes positive and sometimes negative.
Cautions
If inferencing using whisper-ppg speech encoder, you need to set --clip to 25 and -lg to 1. Otherwise it will fail to infer properly.
🤔 Optional Settings
If you are satisfied with the previous results, or if you do not feel you understand what follows, you can skip it and it will have no effect on the use of the model. The impact of these optional settings mentioned is relatively small, and while they may have some impact on specific datasets, in most cases the difference may not be significant.
Automatic f0 prediction
During the training of the 4.0 model, an f0 predictor is also trained, which enables automatic pitch prediction during voice conversion. However, if the results are not satisfactory, manual pitch prediction can be used instead. Please note that when converting singing voices, it is advised not to enable this feature as it may cause significant pitch shifting.
- Set
auto_predict_f0totrueininference_main.py.
Cluster-based timbre leakage control
Introduction: The clustering scheme implemented in this model aims to reduce timbre leakage and enhance the similarity of the trained model to the target's timbre, although the effect may not be very pronounced. However, relying solely on clustering can reduce the model's clarity and make it sound less distinct. Therefore, a fusion method is adopted in this model to control the balance between the clustering and non-clustering approaches. This allows manual adjustment of the trade-off between "sounding like the target's timbre" and "have clear enunciation" to find an optimal balance.
No changes are required in the existing steps. Simply train an additional clustering model, which incurs relatively low training costs.
- Training process:
- Train on a machine with good CPU performance. According to extant experience, it takes about 4 minutes to train each speaker on a Tencent Cloud machine with 6-core CPU.
- Execute
python cluster/train_cluster.py. The output model will be saved inlogs/44k/kmeans_10000.pt. - The clustering model can currently be trained using the gpu by executing
python cluster/train_cluster.py --gpu
- Inference process:
- Specify
cluster_model_pathininference_main.py. If not specified, the default islogs/44k/kmeans_10000.pt. - Specify
cluster_infer_ratioininference_main.py, where0means not using clustering at all,1means only using clustering, and usually0.5is sufficient.
- Specify
Feature retrieval
Introduction: As with the clustering scheme, the timbre leakage can be reduced, the enunciation is slightly better than clustering, but it will reduce the inference speed. By employing the fusion method, it becomes possible to linearly control the balance between feature retrieval and non-feature retrieval, allowing for fine-tuning of the desired proportion.
- Training process: First, it needs to be executed after generating hubert and f0:
python train_index.py -c configs/config.json
The output of the model will be in logs/44k/feature_and_index.pkl
- Inference process:
- The
--feature_retrievalneeds to be formulated first, and the clustering mode automatically switches to the feature retrieval mode. - Specify
cluster_model_pathininference_main.py. If not specified, the default islogs/44k/feature_and_index.pkl. - Specify
cluster_infer_ratioininference_main.py, where0means not using feature retrieval at all,1means only using feature retrieval, and usually0.5is sufficient.
- The
🗜️ Model compression
The generated model contains data that is needed for further training. If you confirm that the model is final and not be used in further training, it is safe to remove these data to get smaller file size (about 1/3).
# Example
python compress_model.py -c="configs/config.json" -i="logs/44k/G_30400.pth" -o="logs/44k/release.pth"
👨🔧 Timbre mixing
Static Tone Mixing
Refer to webUI.py file for stable Timbre mixing of the gadget/lab feature.
Introduction: This function can combine multiple models into one model (convex combination or linear combination of multiple model parameters) to create mixed voice that do not exist in reality
Note:
- This feature is only supported for single-speaker models
- If you force a multi-speaker model, it is critical to make sure there are the same number of speakers in each model. This will ensure that sounds with the same SpeakerID can be mixed correctly.
- Ensure that the
modelfields in config.json of all models to be mixed are the same - The mixed model can use any config.json file from the models being synthesized. However, the clustering model will not be functional after mixed.
- When batch uploading models, it is best to put the models into a folder and upload them together after selecting them
- It is suggested to adjust the mixing ratio between 0 and 100, or to other numbers, but unknown effects will occur in the linear combination mode
- After mixing, the file named output.pth will be saved in the root directory of the project
- Convex combination mode will perform Softmax to add the mix ratio to 1, while linear combination mode will not
Dynamic timbre mixing
Refer to the spkmix.py file for an introduction to dynamic timbre mixing
Character mix track writing rules:
Role ID: Start time 1, end time 1, start value 1, start value 1], [Start time 2, end time 2, start value 2
The start time must be the same as the end time of the previous one. The first start time must be 0, and the last end time must be 1 (time ranges from 0 to 1).
All roles must be filled in. For unused roles, fill 0., 1., 0., 0.
The fusion value can be filled in arbitrarily, and the linear change from the start value to the end value within the specified period of time. The
internal linear combination will be automatically guaranteed to be 1 (convex combination condition), so it can be used safely
Use the --use_spk_mix parameter when reasoning to enable dynamic timbre mixing
📤 Exporting to Onnx
Use onnx_export.py
- Create a folder named
checkpointsand open it - Create a folder in the
checkpointsfolder as your project folder, naming it after your project, for exampleaziplayer - Rename your model as
model.pth, the configuration file asconfig.json, and place them in theaziplayerfolder you just created - Modify
"NyaruTaffy"inpath = "NyaruTaffy"in onnx_export.py to your project name,path = "aziplayer"(onnx_export_speaker_mix makes you can mix speaker's voice) - Run onnx_export.py
- Wait for it to finish running. A
model.onnxwill be generated in your project folder, which is the exported model.
Note: For Hubert Onnx models, please use the models provided by MoeSS. Currently, they cannot be exported on their own (Hubert in fairseq has many unsupported operators and things involving constants that can cause errors or result in problems with the input/output shape and results when exported.)
📎 Reference
| URL | Designation | Title | Implementation Source |
|---|---|---|---|
| 2106.06103 | VITS (Synthesizer) | Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech | jaywalnut310/vits |
| 2111.02392 | SoftVC (Speech Encoder) | A Comparison of Discrete and Soft Speech Units for Improved Voice Conversion | bshall/hubert |
| 2204.09224 | ContentVec (Speech Encoder) | ContentVec: An Improved Self-Supervised Speech Representation by Disentangling Speakers | auspicious3000/contentvec |
| 2212.04356 | Whisper (Speech Encoder) | Robust Speech Recognition via Large-Scale Weak Supervision | openai/whisper |
| 2110.13900 | WavLM (Speech Encoder) | WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing | microsoft/unilm/wavlm |
| 2305.17651 | DPHubert (Speech Encoder) | DPHuBERT: Joint Distillation and Pruning of Self-Supervised Speech Models | pyf98/DPHuBERT |
| DOI:10.21437/Interspeech.2017-68 | Harvest (F0 Predictor) | Harvest: A high-performance fundamental frequency estimator from speech signals | mmorise/World/harvest |
| aes35-000039 | Dio (F0 Predictor) | Fast and reliable F0 estimation method based on the period extraction of vocal fold vibration of singing voice and speech | mmorise/World/dio |
| 8461329 | Crepe (F0 Predictor) | Crepe: A Convolutional Representation for Pitch Estimation | maxrmorrison/torchcrepe |
| DOI:10.1016/j.wocn.2018.07.001 | Parselmouth (F0 Predictor) | Introducing Parselmouth: A Python interface to Praat | YannickJadoul/Parselmouth |
| 2306.15412v2 | RMVPE (F0 Predictor) | RMVPE: A Robust Model for Vocal Pitch Estimation in Polyphonic Music | Dream-High/RMVPE |
| 2010.05646 | HIFIGAN (Vocoder) | HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis | jik876/hifi-gan |
| 1810.11946 | NSF (Vocoder) | Neural source-filter-based waveform model for statistical parametric speech synthesis | openvpi/DiffSinger/modules/nsf_hifigan |
| 2006.08195 | Snake (Vocoder) | Neural Networks Fail to Learn Periodic Functions and How to Fix It | EdwardDixon/snake |
| 2105.02446v3 | Shallow Diffusion (PostProcessing) | DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism | CNChTu/Diffusion-SVC |
| K-means | Feature K-means Clustering (PreProcessing) | Some methods for classification and analysis of multivariate observations | This repo |
| Feature TopK Retrieval (PreProcessing) | Retrieval based Voice Conversion | RVC-Project/Retrieval-based-Voice-Conversion-WebUI | |
| whisper ppg | whisper ppg | PlayVoice/whisper_ppg | |
| bigvgan | bigvgan | PlayVoice/so-vits-svc-5.0 |
☀️ Previous contributors
For some reason the author deleted the original repository. Because of the negligence of the organization members, the contributor list was cleared because all files were directly reuploaded to this repository at the beginning of the reconstruction of this repository. Now add a previous contributor list to README.md.
Some members have not listed according to their personal wishes.
 MistEO |
 XiaoMiku01 |
 しぐれ |
 TomoGaSukunai |
 Plachtaa |
 zd小达 |
 凍聲響世 |
📚 Some legal provisions for reference
Any country, region, organization, or individual using this project must comply with the following laws.
《民法典》
第一千零一十九条
任何组织或者个人不得以丑化、污损,或者利用信息技术手段伪造等方式侵害他人的肖像权。未经肖像权人同意,不得制作、使用、公开肖像权人的肖像,但是法律另有规定的除外。未经肖像权人同意,肖像作品权利人不得以发表、复制、发行、出租、展览等方式使用或者公开肖像权人的肖像。对自然人声音的保护,参照适用肖像权保护的有关规定。
第一千零二十四条
【名誉权】民事主体享有名誉权。任何组织或者个人不得以侮辱、诽谤等方式侵害他人的名誉权。
第一千零二十七条
【作品侵害名誉权】行为人发表的文学、艺术作品以真人真事或者特定人为描述对象,含有侮辱、诽谤内容,侵害他人名誉权的,受害人有权依法请求该行为人承担民事责任。行为人发表的文学、艺术作品不以特定人为描述对象,仅其中的情节与该特定人的情况相似的,不承担民事责任。